Part 3 - Building with Langchain, Agents and Action Plans
LangChain's agents are the superheroes of LLM-based applications, making decisions and executing actions like pros! They dynamically interact with tools, process information step-by-step, and develop powerful action plans. Behind this wizardry lies some serious mathematical firepower. In this blog, we'll explore how LangChain agents operate, how they make decisions, and how mathematical concepts like Markov Decision Processes (MDPs) help them navigate the world of actions and decisions!

Agent Decision Making
LangChain agents don’t just sit around waiting for input—they’re smart decision-makers, carefully picking which tools or processes to invoke based on the current situation. Think of them as intelligent assistants who know when and how to get things done.
Introduction to Markov Decision Processes (MDPs)
How do agents figure out what to do next? We use Markov Decision Processes (MDPs) to mathematically model decision-making. An MDP is like a roadmap that guides the agent through different states based on the actions it takes. It’s defined by five components:

- \(S\): The set of possible states the system can be in (e.g., whether it's the beginning of a conversation or midway through a complex task).
- \(A\): The set of available actions (e.g., search for data, calculate a result).
- \(P(s' | s, a)\): The probability of moving to state \(s'\) from state \(s\) when taking action \(a\).
- \(R(s, a)\): The reward received for taking action \(a\) in state \(s\).
- \(\gamma \in [0, 1]\): The discount factor for future rewards (basically, how much the agent cares about future rewards).
The agent’s goal? Maximize the expected total reward over time:
\[ V(s) = \mathbb{E}\left[\sum_{t=0}^\infty \gamma^t R(s_t, a_t)\right] \]
Agent Decision Rule
Now, how does the agent pick the right action? That’s where policies come in! A policy \(\pi(a | s)\) defines the probability of taking action \(a\) in state \(s\):
\[ P(s', a | s) = \pi(a | s) P(s' | s, a) \]
The agent always aims to choose the action that will give it the maximum expected reward:
\[ a^* = \arg\max_a Q(s, a) \]
where \(Q(s, a)\) is the action-value function:
\[ Q(s, a) = R(s, a) + \gamma \sum_{s'} P(s' | s, a) V(s') \]
Tools as Functions
Think of tools in LangChain like special gadgets agents use to complete their tasks. These tools are essentially mathematical functions that take inputs and give outputs.
For example:
- A calculator tool takes an arithmetic expression and returns the result.
- A search engine tool takes a query and returns a list of documents.
Mathematically, a tool is a function \(f\):
\[ f: \text{Inputs} \to \text{Outputs} \]
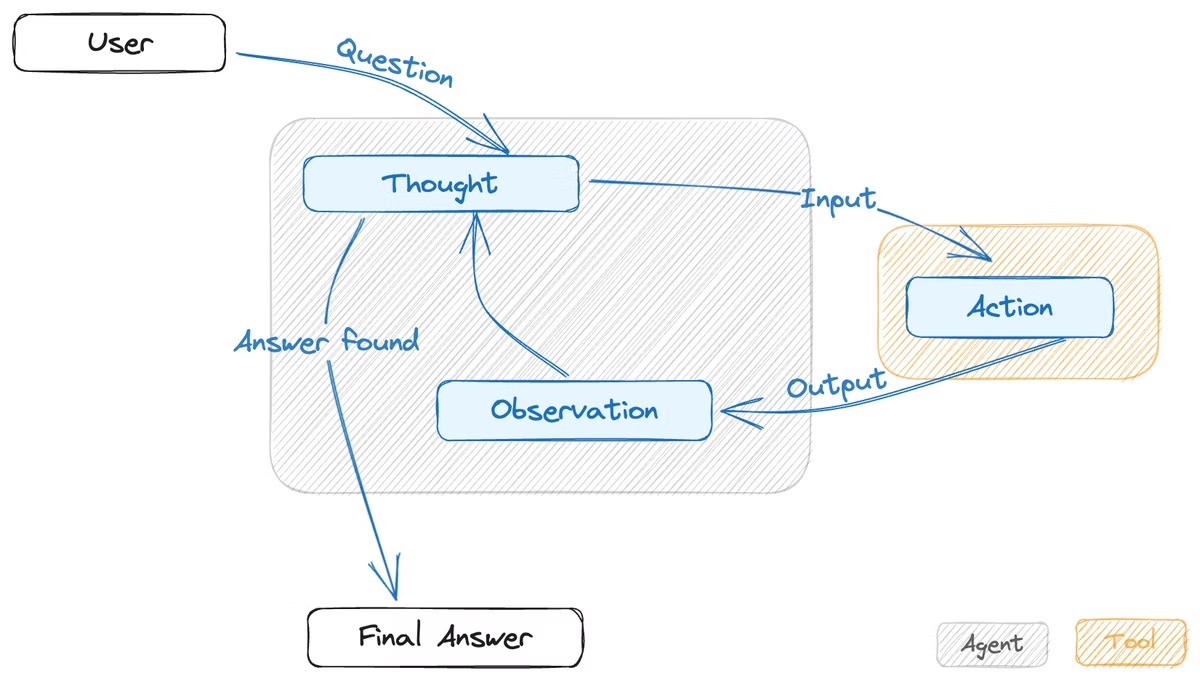
Zero-Shot and ReAct Patterns
LangChain agents use different reasoning patterns to make smart choices, and two of the most powerful are Zero-Shot and ReAct.
Zero-Shot ReAct Pattern
The Zero-Shot ReAct (Reason and Act) pattern is like an agent thinking and acting on the fly! For each step, the agent reasons about the current situation, picks an action, and sees the outcome.
Iterative Reasoning Equation
At each step, the agent figures out the best thing to do based on the current context:
\[ \text{Thought}_t = \arg\max_{\text{Response}} P(\text{Response} | \text{Context}) \]
Then, the agent takes an action:
\[ \text{Action}_t = \pi(a_t | s_t) \]

Afterward, the agent updates the context with the new information:
\[ \text{Context}_{t+1} = \text{Context}_t + \text{Observation}_t \]
ReAct Example: Calculating and Searching
Let’s break it down step-by-step:
- Input: "What is the population of India in 2023?"
- Thought: "I need to look up the latest population data."
- Action: Call a search engine with the query "India population 2023."
- Observation: "The population of India in 2023 is approximately 1.42 billion."
- Thought: "I have the answer now!"
- Final Answer: "The population of India in 2023 is approximately 1.42 billion."
Action Plan Generation
To achieve complex goals, LangChain agents can create action plans—carefully organized sequences of actions. These plans are like step-by-step instructions to reach the desired outcome.
Mathematical Model for Tool Selection
Let’s say an agent needs to use \(n\) tools to complete a task. It must decide the optimal sequence of tools \(T = [t_1, t_2, \dots, t_n]\). The agent’s job is to choose the sequence that maximizes the expected utility:
\[ T^* = \arg\max_T \mathbb{E}[U(T, C)] \]
where:
- \(U(T, C)\) is the utility of using sequence \(T\) in context \(C\).
- \(\mathbb{E}\) represents the expected value over all possible outcomes.
The agent picks each tool based on its relevance to the current context:
\[ t_i = \arg\max_{t \in \mathcal{T}} P(t | C_i) \]
where \(\mathcal{T}\) is the set of available tools.
Enhanced Problem Solving with Function Calls
LangChain agents also enhance their problem-solving skills by dynamically calling external functions, like calculators or APIs.
Example: Using a Calculator Tool
Imagine the agent gets a question like, "What is 4523 × 768?" Here’s how it would work:
- Thought: "I need to calculate the product of 4523 and 768."
- Selects Action: Use the calculator tool:
- Inputs Expression: \(x = 4523 \times 768\)
- Receives Output: \(3,473,664\)
- Finalizes Thought: "The result is 3,473,664."
\[ f_{\text{calc}}(x) = \text{eval}(x) \]
Example: Searching for Information
Now, let’s say the agent gets the query, "Find the CEO of OpenAI."
- Thought: "I need to search for the CEO of OpenAI."
- Selects Action: Use the search engine tool:
- Input Query: \(q = \text{"CEO of OpenAI"}\)
- Observation: "Sam Altman is the CEO of OpenAI."
- Final Answer: "The CEO of OpenAI is Sam Altman."
\[ f_{\text{search}}(q) = \text{Results}(q) \]
Conclusion
LangChain agents are true problem solvers, equipped with powerful decision-making abilities, dynamic action plans, and the ability to call external tools. With mathematical foundations like MDPs, ReAct reasoning, and action plan generation, these agents can take on complex tasks effortlessly. In the next blog, we will dive into LangChain’s memory system, which stores context to make conversations even more coherent and task execution even smoother.


Comments
Post a Comment